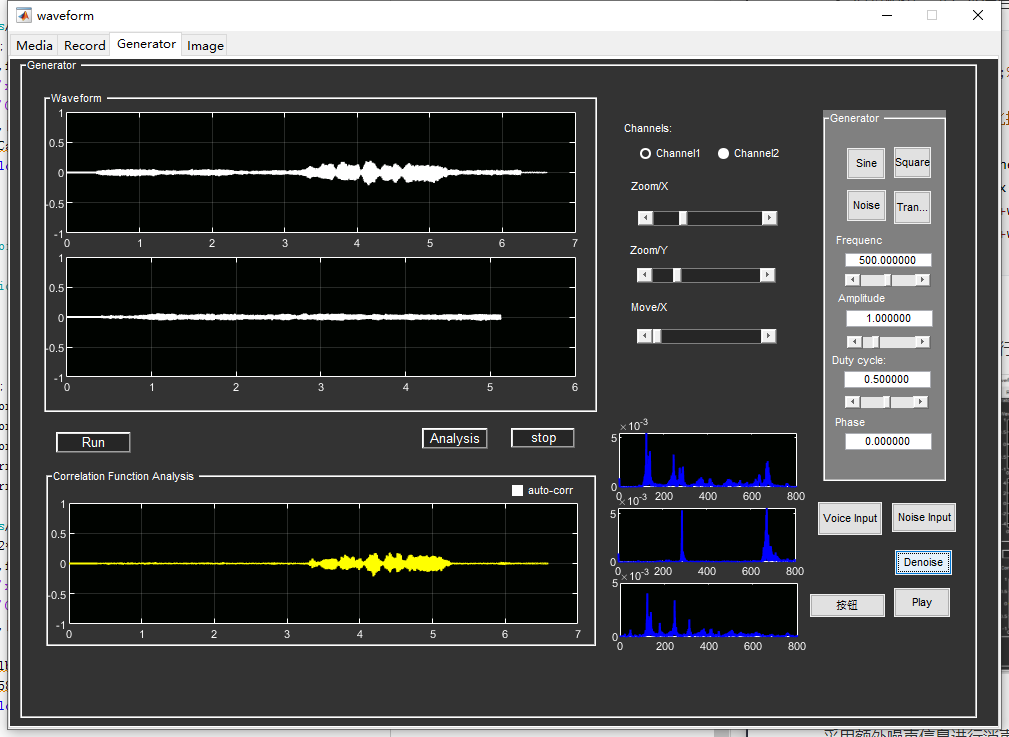
谱减法实现
降噪原理
谱减法的降噪方式简单来说就是从带噪声的语音频率信息中减去噪声频率的部分, 即从语音信号幅度谱中减去噪声的估值幅度谱, 相当于对噪声进行了均衡处理。
这里采用传统的谱减法进行实现
谱减法原理图
几个假设假设:
- 噪声在频域是加性的
- 背景噪声近似是稳态的
- 主要噪声可以仅仅通过语音普幅度中翘曲噪声实现
程序实现
- 首先根据输入参数不同进行函数重载
- 为了方便处理 ,将可能双通道的音频合成为单通道 ,记录在x中
matlab没有函数重载, 但可以通过 nargin 判断参数个数, 或者 inputParser 进行选择输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| function dnY = denoise(y,fs,varargin)
narginchk(0,2);
if size(y,2) == 2
x = mean(y,2);
else
x = y;
end
|
- 对长段音频信号直接进行分析是不太可取的, 并且也没有这个必要。因为短段语音信息可以认为是稳定的, 所以我们可以对音频信号进行分帧处理, 一般每帧长度取 20-30ms
- 因为直接截断相当于添加了一个矩形窗函数, 矩形窗函数的旁瓣较高, 频率泄漏相较严重, 所以为每段信号加上汉宁窗, 可以缓解频率泄漏。
- 由于汉宁窗会丢失掉前后一部分的信息,所以每次移动窗的距离, 取21或者31窗长作为移窗距离, 以便在前后窗可以补全缺失的信息。
- 对语音信息进行快速傅里叶变换得到频谱数据, 因为人耳对相位信息不敏感, 故可以记录带噪声时的相位信息, 用作降噪后还原语音信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SizeX = length(x);
wl = floor(0.03*fs);
wm = floor(wl/2);
N = floor((SizeX-wl)/wm);
for i = 1:N
xh=x((i-1)*wm+1:(i-1)*wm+wl).*hamming(wl);
XH=fft(xh,wl);
PSD(i,:)=abs(XH).^2;
phase(i,:)=angle(XH);
end
|
- 假设语音数据 Yw(w) 包括目标声音数据 Sw(w) 和噪声 Nw(w) 则对于功率谱有
∣Yw(w)∣2=∣Sw(w)∣2+∣Nw(w)∣2+Sw(w)Nw∗(w)+Sw∗(w)Nw(w)
假设 s 和 n 相互独立, 则相互统计均值为零, 可以估计原始目标数据为
∣S^w(w)∣2=∣Yw(w)∣2−E(∣Nw(w)∣2)
- 当输入参数为3个时,意味着输入了参考噪声信息 ,采取上述相同的操作获得噪声的功率谱估计值E(∣Nw(w)∣2)
这里发现估计的噪声功率普均衡效果不佳, 故这里仅仅通过乘以了一个系数以提高效果, 效果稍微好了一些, 但是目标声音也受到了一定影响, 可能通过其他算法可以优化.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| switch nargin
case 2
noiseP = (sum(PSD(68:134,:))/67).*3;
case 3
noisedata = varargin{1};
if size(noisedata,2) == 2
Noise = mean(noisedata,2);
else
Noise = noisedata;
end
SizeN = length(Noise);
wlN = floor(0.03*fs);
wmN = floor(wlN/2);
NN = floor((SizeN-wlN)/wmN);
for i = 1:NN
nh=Noise((i-1)*wmN+1:(i-1)*wmN+wlN).*hamming(wlN);
NH=fft(nh,wlN);
NPSD(i,:)=abs(NH).^4;
end
noiseP = sum(NPSD(71:NN-70,:))/(NN-140).*3;
end
for i = 1:N
PSD(i,:) = PSD(i,:)-noiseP;
PSD(i,find(PSD(i,:)<0))=0;
end
|
- 对处理后的信息进行逆变换(返回频谱、添加相位信息、傅里叶逆变换、消窗), 得到目标语音帧.
- 对每帧语音进行平滑合并 ,得到目标语音
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
for i = 1:N
PSD(i,:)=sqrt(PSD(i,:));
XHA = PSD(i,:).*exp(j*ang(i,:));
dnx(i,:) = real(ifft(XHA))/hamming(wl)';
end
dny = dnx(1,:)';
pbeg = wl-wm;
pend = wl;
for i = 2:N
dny(pbeg:pend) = (dny(pbeg:pend)+dnx(i,1:wm)')/2;
dny=[dny;dnx(i,wl-wm:wl)'];
pbeg = pbeg+wl;
pend = pend+wl;
end
|
实现效果
采用前1-2s内噪声信息进行消声
采用额外噪声信息进行消声